
Towards the Reverse Engineering of DNN Structures on Heterogeneous Shared Cache Systems
Published:
Overview
This project was completed as part of my master’s thesis at Iowa State University under the guidance of Dr. Joseph Zambreno, Dr. Berk Gulmezoglu, and Dr. Henry Duwe.
The project explores the exploitability of a shared last-level cache (LLC) on a 6th-generation Intel SoC. The goal of the project was to demonstrate that it is possible to characterize the application accelerated by the integrated graphics of the SoC through a timing side-channel on the CPU cores.
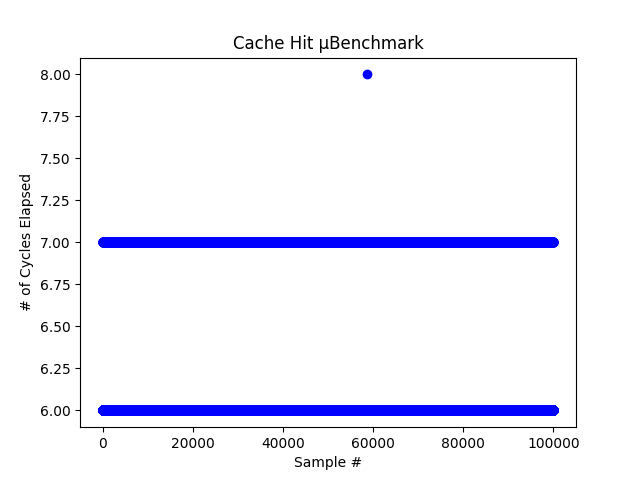
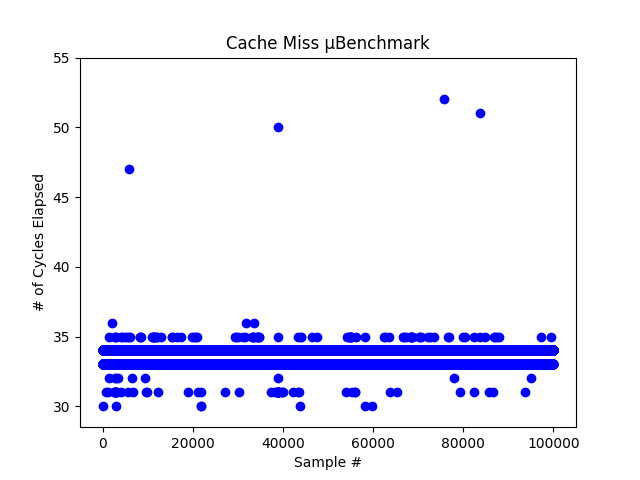
Timing side channels require knowledge of the characteristics of your specific system. A side-channel leveraging a cache requires two baseline values; the time it takes for your system to complete a cache hit, and the time it takes for a cache miss. I used the RDTSC instruction available in the x86 instruction set to measure the cycle count between a memory access. I also forced cache misses using the CLFLUSH instruction. These two micro-benchmarks allowed me to establish a baseline threshold for what is considered a cache hit or cache miss.
Observing GPU Activity
With a baseline set, we can now perform a timing side-channel on the shared last-level cache of our Intel SoC. The timing side channel works by purposefully filling up a cache set with data and allowing the target application to run, the cache set addresses are then accessed again. During the second access, we time how long it takes to access the data. An access time longer than our ground truth means the data was expelled from the cache and we conclude that the target application accessed that cache location.
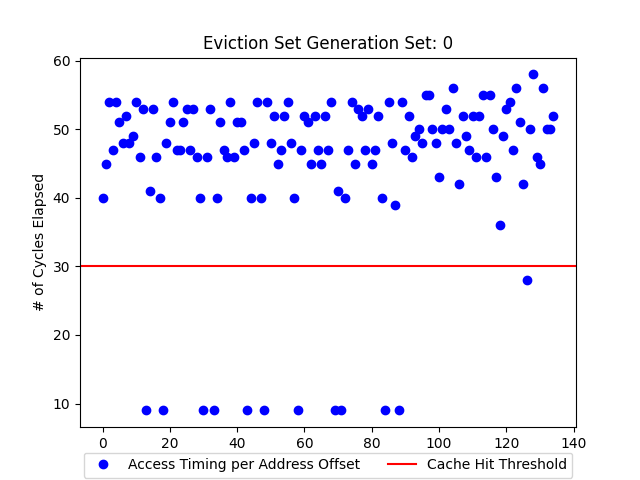
Constructing a Cache Set
We construct our cache set using an algorithmic process that procedurally fills more cache lines until we experience a cache miss. We can then take the number of cache addresses from this process and find which addresses belong to a set by accessing all but one of the addresses found in the previous steps. We then observe the time it takes to access the first address. If a cache hit occurs we know the ommited address is part of our cache set.
Performing the Side-Channel
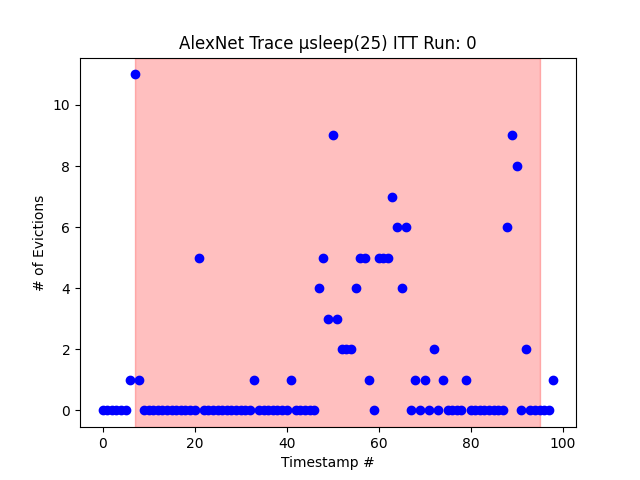
With a cache set constructed, we can now target the iGPU activity. We choose to run neural network inference accelerated by the iGPU of our SoC. We use Intel’s OpenVINO to deploy trained models on our system. A wrapper application launched the openVINO application and ran our side channel on the CPU utilizing standard POSIX threads. The wrapper application was also running with Intel VTune profiler to confirm when GPU activity was occurring and which side-channel traces overlapped with the GPU execution time.
Conclusions & Future Work
Extending the data captured from our iGPU over a wider range of neural networks we showed that neural networks leave different traces in cache accesses correlating with the time when heavier memory-intensive computations were occuring for that specific network. To further extend this work we would consider training a linear regression model which can predict which application is running on the iGPU based on the captured trace, or at least determine which application has the closest matches trace to that of the input. Additionally, we can consider running other GPGPU applications such as scientific accelerated work, and finally, we would consider reversing the side-channel and attempting to observe CPU activity from a GPGPU application.